Frustrated with Your Kafka Costs and Reliability?
Superstream is your trusted Apache Kafka Assistant.
Automatically ensure your Apache Kafka is reliable and cost-efficient.
Trusted by Leading Kafka Teams
Kafka Optimization Across All Major Vendors
Cut Confluent CKU, Storage & Transfer Costs
Superstream helps Confluent users cut CKU, storage, and data transfer costs by cleaning idle resources, tuning topic policies, reducing client requests, and optimizing client behavior for a lower network footprint
AWS MSK Optimization: Stable, Reliable & Cost-Efficient
Superstream improves AWS MSK reliability and lowers costs by running daily health scans, cleaning idle resources, optimizing topic policies, reducing client requests, cutting data transfer, and right-sizing Kafka cluster infrastructure
Aiven Kafka Optimization for Healthier, Cost-Efficient Clusters
Superstream helps Aiven users cut costs and improve stability by right-sizing plans, optimizing storage, reducing data transfer, and enforcing topic policies for healthier, more efficient clusters
Kafka Optimization for Redpanda
Superstream optimizes Redpanda clusters — by running daily health scans, cleaning idle resources, optimizing topic policies, reducing client requests and cutting data transfer
Kafka Optimization for Self-Hosted or Any Other Kafka Flavor
Superstream optimizes any Kafka deployment not listed separately — including WarpStream, Instaclustr, or self-hosted Kafka clusters — by running daily health scans, cleaning idle resources, optimizing topic policies, reducing client requests and cutting data transfer

Deploy a local agent to communicate securely with your Kafka cluster
Connect your clusters through the Superstream Console
View Health Report and Actionable Kafka Optimization Insights Within Minutes
Choose which tasks to automate and where—cluster by cluster
Keep Kafka Safe, Reliable, and cost-efficient Automatically
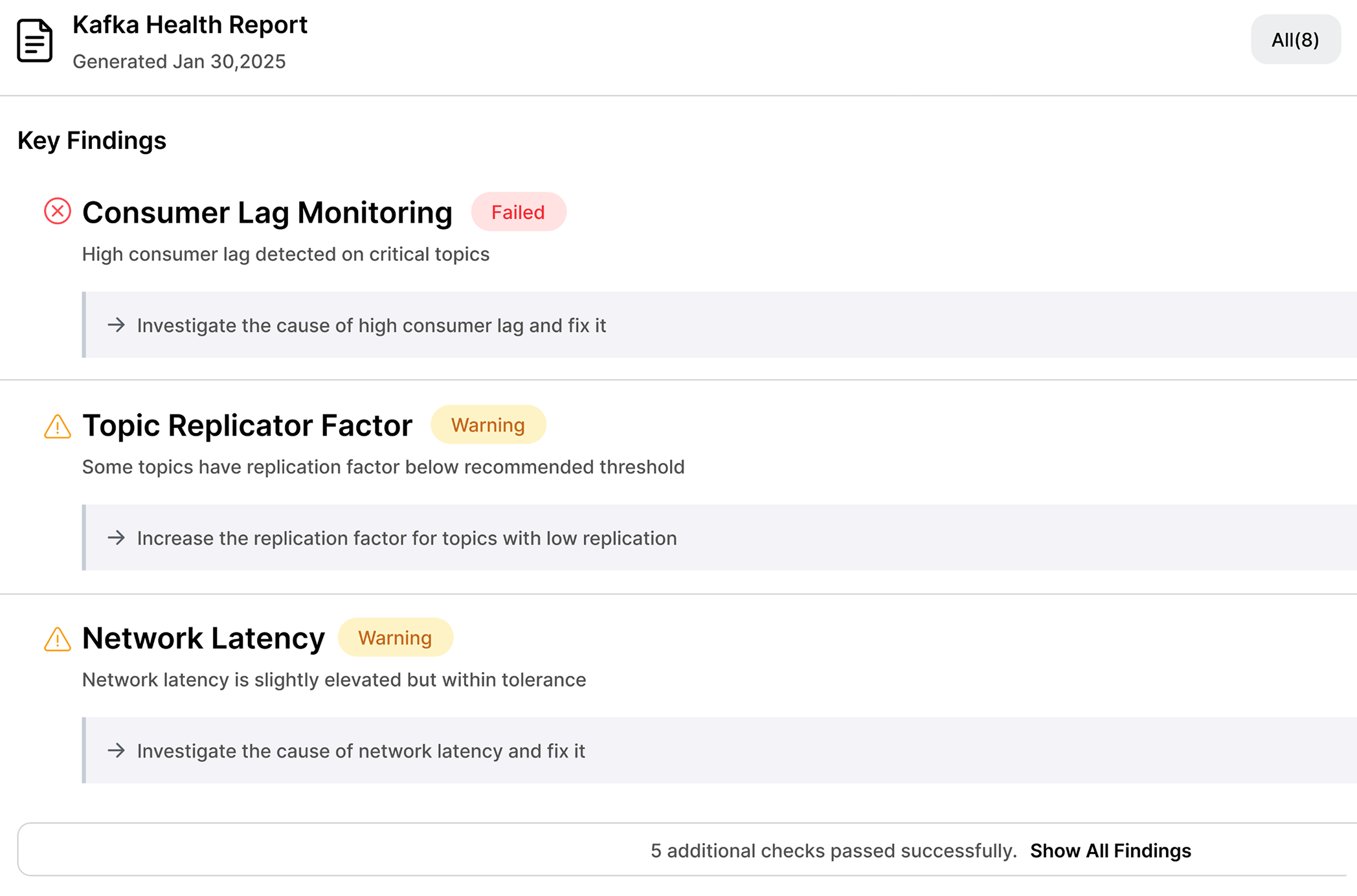
Continuously monitors brokers, topics, partitions, and consumer groups—detecting misconfigurations, bloat, and risks before they impact production. It automatically flags issues and enforces best practices through clear recommendations. Built for optimizing Kafka at scale.
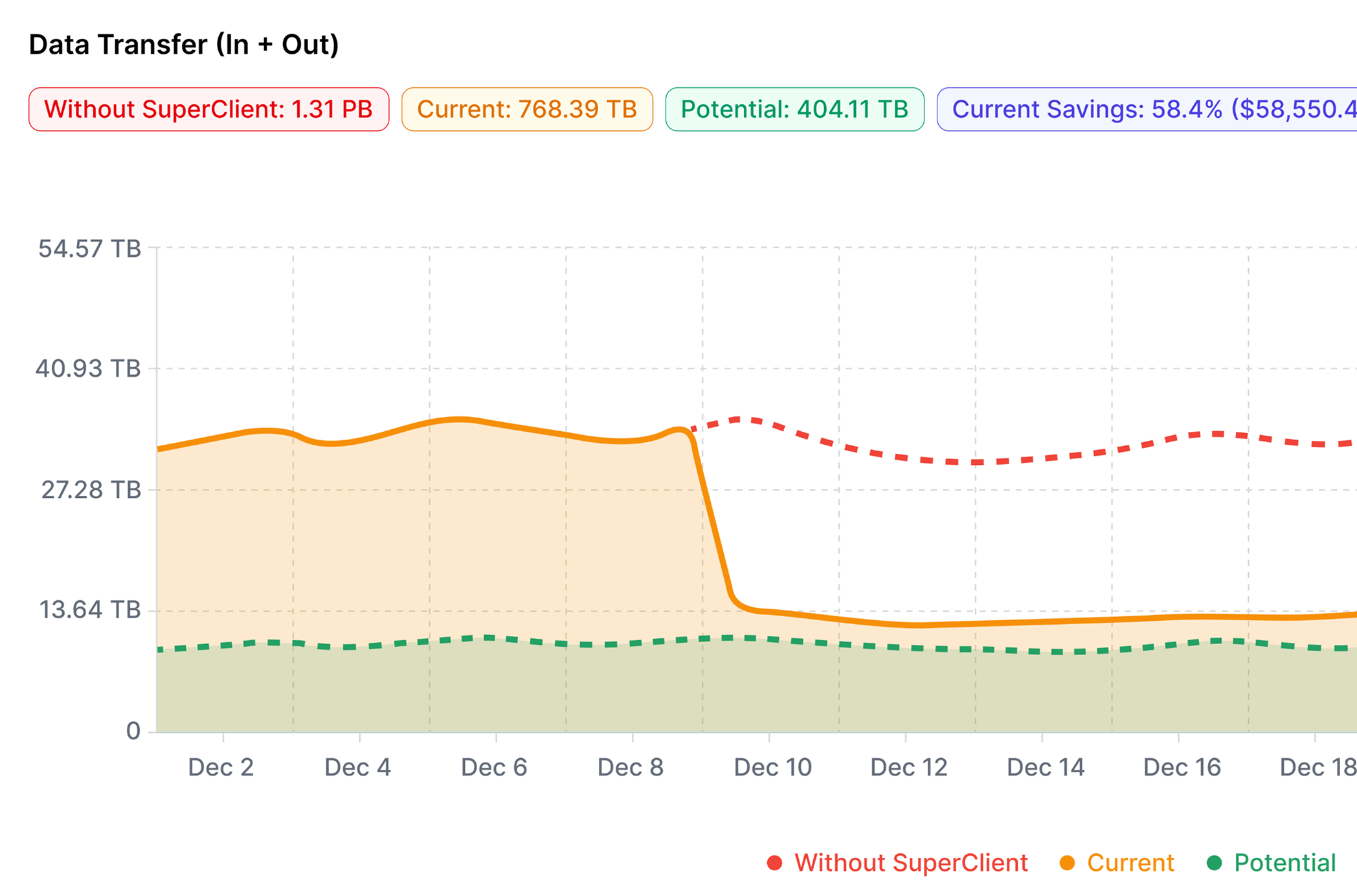
Fine-tunes client configurations to reduce data transfer and automatically optimize Kafka performance. By adapting producer settings to workload patterns, it delivers Kafka network traffic reduction without code changes. This also eases pressure on brokers, prevents inefficient clients from overwhelming your Kafka cluster, and minimizes storage costs.
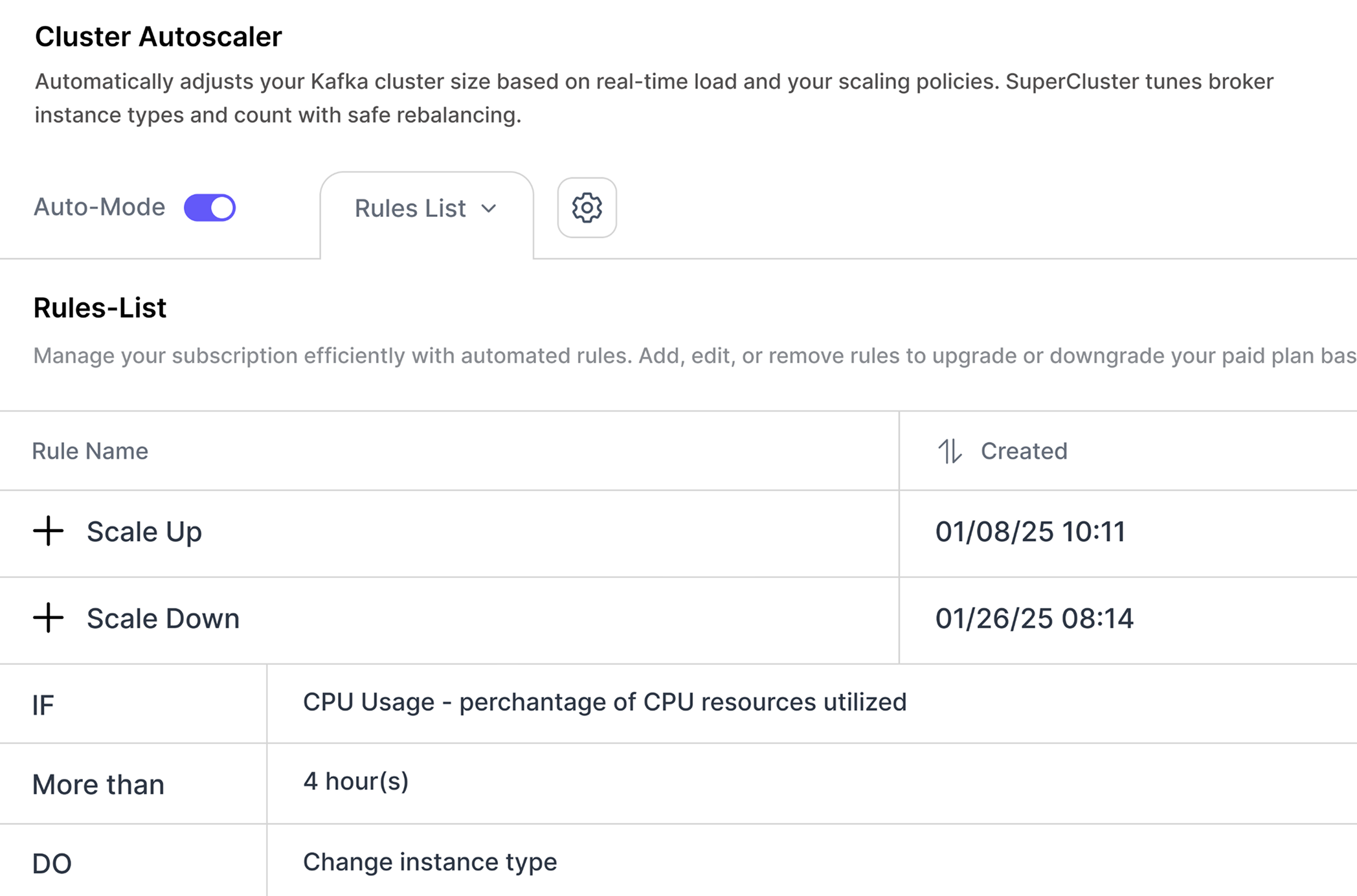
Intelligently optimize Kafka by adjusting broker count, instance types, and rebalancing for MSK, or streamlining plan selection in Aiven — based on usage patterns and policies you define, ensuring your Kafka stays right-sized and cost-efficient.
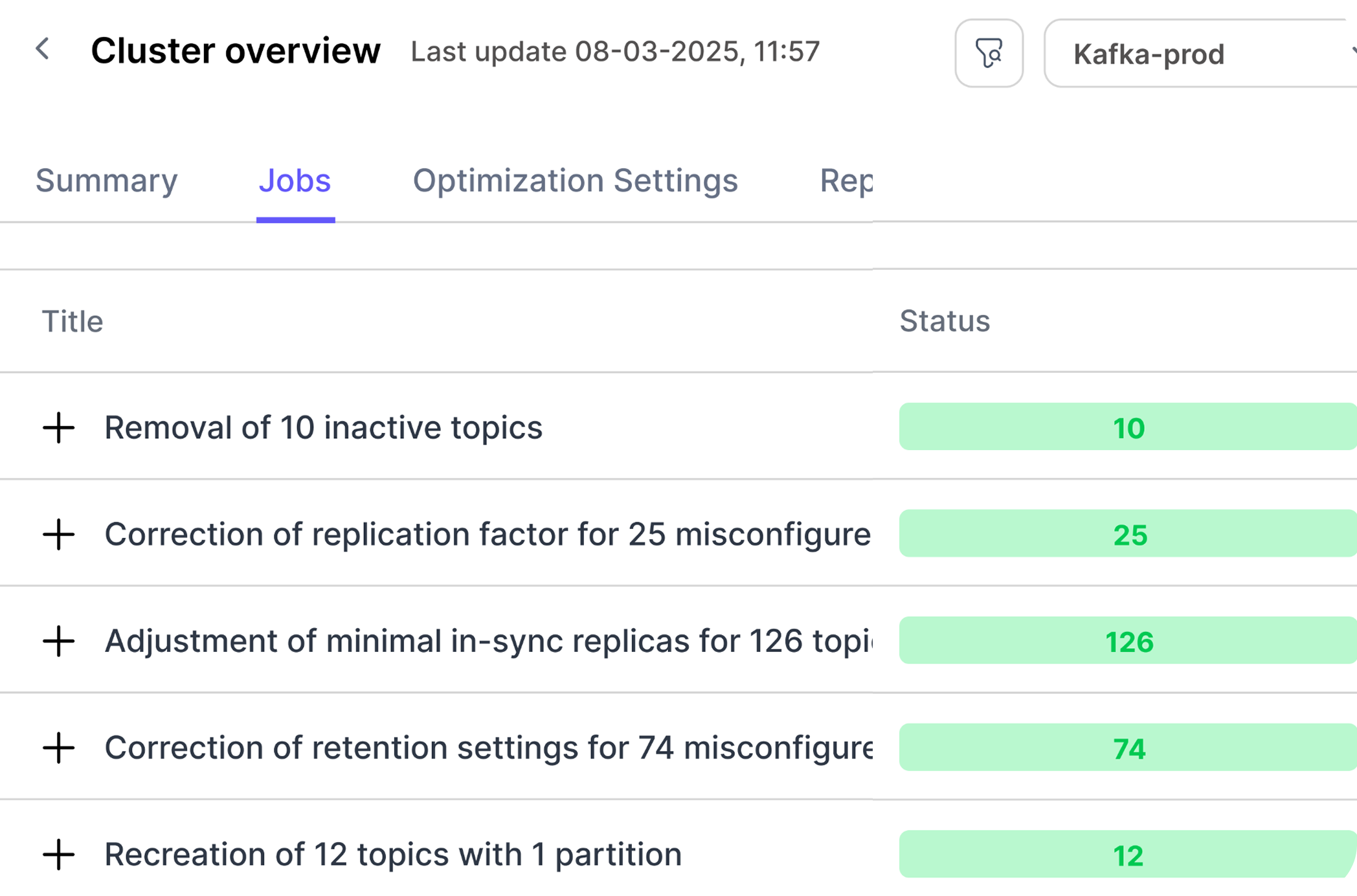
Auto-remediates health issues—including misconfigured or idle topics and unused consumer groups—based on policies you define. Reduce clutter, free up resources, and improve Kafka cluster efficiency—preventing issues before they impact stability while cutting Kafka costs.
Choose the Right Path for Your Kafka Needs
Whether you're optimizing an existing Kafka deployment or securing mission-critical recovery, Superstream has you covered.
Expert Kafka Architecture, Optimization & Implementation
Get end-to-end Kafka guidance — from readiness assessments to architecture design, cost optimization, scalability improvements, and ongoing advisory.
Architecture & scaling assessments
Cost, throughput & reliability optimization
Implementation & modernization
Operational and SRE-focused advisory
Fully Managed Topic-Level Disaster Recovery — In Your Cloud
Protect critical Kafka workloads with automated, low-latency replication, strong RPO/RTO guarantees, and full data sovereignty in your own environment.
Topic-level HA/DR
RPO ≤ 5 seconds, RTO ~10 minutes
BYOC deployment for sovereignty & control
Monitoring, orchestration & quarterly DR tests
Teams With Optimized Kafka
And Easier lives
“Superstream took a huge load off our plates. We used to spend hours tuning Kafka and managing cost optimizations manually. Now it just works in the background—smart, safe, and way more efficient.”

FinOps Engineer // Orca Security
“We plugged Superstream in, and within days, it started surfacing config issues and cost sinks we had no idea existed. The auto-tuning is legit—performance went up and our network overhead dropped noticeably.”

DevOps TL // Solidus Labs
“Superstream has dramatically lowered our AWS MSK (Kafka) costs and increased our visibility—with zero impact on production.”

VP R&D // Orca Security
“I was skeptical at first, but Superstream quickly proved its value. It understands our workload patterns better than we do and keeps our Kafka lean without us lifting a finger. It’s like having another engineer on the team.”

Dev Team Leader // eToro
“Very relatable! Kafka cleanup can be a nightmare—love how Superstream focuses on real-time optimization and actionable fixes.”

Senior Data Engineer // Mission City Federal Credit Union
“Superstream took a huge load off our plates. We used to spend hours tuning Kafka and managing cost optimizations manually. Now it just works in the background—smart, safe, and way more efficient.”
FinOps Engineer // Orca Security
“We plugged Superstream in, and within days, it started surfacing config issues and cost sinks we had no idea existed. The auto-tuning is legit—performance went up and our network overhead dropped noticeably.”
DevOps TL // Solidus Labs
“Superstream has dramatically lowered our AWS MSK (Kafka) costs and increased our visibility—with zero impact on production.”
VP R&D // Orca Security
“I was skeptical at first, but Superstream quickly proved its value. It understands our workload patterns better than we do and keeps our Kafka lean without us lifting a finger. It’s like having another engineer on the team.”
Dev Team Leader // eToro
“Very relatable! Kafka cleanup can be a nightmare—love how Superstream focuses on real-time optimization and actionable fixes.”
Senior Data Engineer // Mission City Federal Credit Union
“Superstream took a huge load off our plates. We used to spend hours tuning Kafka and managing cost optimizations manually. Now it just works in the background—smart, safe, and way more efficient.”
FinOps Engineer // Orca Security
“We plugged Superstream in, and within days, it started surfacing config issues and cost sinks we had no idea existed. The auto-tuning is legit—performance went up and our network overhead dropped noticeably.”
DevOps TL // Solidus Labs
“Superstream has dramatically lowered our AWS MSK (Kafka) costs and increased our visibility—with zero impact on production.”
VP R&D // Orca Security
“I was skeptical at first, but Superstream quickly proved its value. It understands our workload patterns better than we do and keeps our Kafka lean without us lifting a finger. It’s like having another engineer on the team.”
Dev Team Leader // eToro
“Very relatable! Kafka cleanup can be a nightmare—love how Superstream focuses on real-time optimization and actionable fixes.”
Senior Data Engineer // Mission City Federal Credit Union




