


















How to reduce AWS MSK costs
Optimize Your Budget: Proven Strategies to Cut AWS MSK Expenses

Amazon Managed Streaming for Apache Kafka (AWS MSK) is a great managed solution for Kafka.
It offers two operating models: provisioned and serverless.
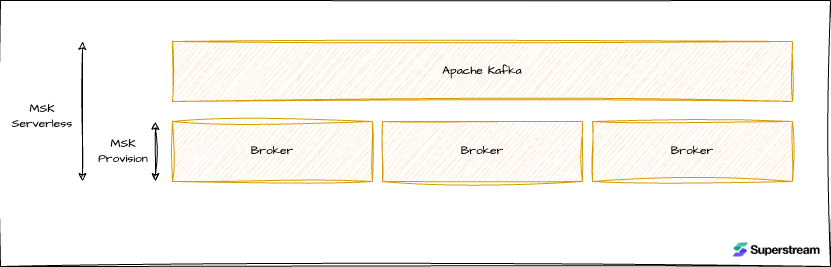
AWS MSK Provisioned
AWS takes care of the infrastructure, covering tasks like version upgrades, lifecycle management, monitoring, scaling (within certain limits), and security. While this is extensive, you still need to be mindful of not overloading the cluster or misusing Kafka at the application layer. I’d call it “Kafka for pros,” though because this type of deployment predates the serverless model. Most MSK users—whether advanced or not—will likely use the provisioned option.
Billed by (computing type x hours) + storage + traffic.
AWS MSK Serverless
Serverless is fairly new and recently became available for MSK users to use. Both layers are managed (app and infrastructure), and you have to be really creative to break it. The entire stack is self-delivered and managed, and you pay for the Kafka-level resources you use: storage/hr, partitions/hr, and traffic. It depends on the use case, but in most of the cases I saw, it will be by far more expensive to use in comparison to MSK Provisioned.
How to reduce AWS MSK costs
1. Dynamically resize your cluster to fit the current workload
Compute is one of the main cost drivers in AWS MSK, meaning the chosen instance type. AWS offers various instance types, from the lower-cost Kafka.m5.large and even Kafka.t3.small to the high-performance Kafka.m5.24xlarge. You can select the smallest instance that meets your workload by continuously and carefully analyzing your throughput and latency requirements.
- Use Amazon CloudWatch to monitor broker performance, including CPU, memory, and disk usage. If you’re unsure of your requirements, start with smaller instances and scale up as necessary.
- Consider redistributing workloads and partitions or adjusting Kafka configurations (like the number of partitions and replication factor) to avoid oversized brokers. This can lead to bigger nodes with higher costs for no good reason.
- Remember to always check the CPU utilization. Below 50%, that’s an opportunity to scale down, above and less than 80%—stay where you are. Remember, 40% average CPU utilization does not necessarily mean that you need more “horsepower.”
2. Dynamically optimize the number of brokers, and don’t forget to rebalance once it is done!
The number of brokers in your cluster directly impacts cost. For high availability, AWS MSK recommends having three brokers across three Availability Zones, but you may be able to reduce this number for smaller or non-critical workloads.
- Test Smaller Configurations: For development, staging, or less critical applications, try clusters with fewer brokers or use a single Availability Zone.
- Downsize as Workloads Shrink: If you notice reduced data flow or need to adjust to lower demand, resize your MSK cluster to reduce the broker count.
3. Leverage AWS MSK Tiered Storage
AWS MSK offers a tiered storage option, allowing you to store historical data at a lower cost in Amazon S3 while retaining frequently accessed data on disk. By offloading older data to tiered storage, you can reduce the disk size requirements on brokers.
4. Set Appropriate Retention Policies
- Avoid infinite retention policies. You don’t need that.
- Determine the maximum retention period required for data in Kafka and ensure that all topics comply with this limit.
5. Optimize Data Transfer
Data transfer costs can accumulate when moving data between AWS AZs, regions, or outside to the internet. Here are few critical tricks to reduce that:
- Limit Cross-Region Data Replication: While cross-region replication can improve availability and disaster recovery, it also incurs additional transfer costs. Use this feature sparingly or consider alternatives, like using local clusters.
- Reduce network traffic costs of your Amazon MSK consumers with rack awareness and fetch from closest replicas. A full guide can be found here: https://aws.amazon.com/blogs/big-data/reduce-network-traffic-costs-of-your-amazon-msk-consumers-with-rack-awareness/
6. Use Autoscaling to Manage Demand Fluctuations
AWS MSK does not allow you to set up autoscaling policies to increase or decrease the number of brokers based on traffic. This dynamic approach can save you money by reducing broker counts during low-demand periods.
You can achieve that by using Superstream autoscaler for AWS MSK. More information can be found here: https://superstream.ai/vendors/optimizing-aws-msk-with-superstream/
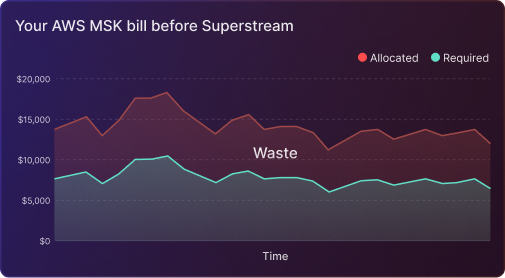
7. Monitor Costs and Optimize Regularly
Lastly, regular monitoring of your AWS MSK usage and associated costs can reveal optimization opportunities.
No content available.
Related Articles

Warpstream is Dead. Long Live Cost Awareness
Embracing Cost-Aware Strategies After Warpstream

4 things wrong with most Kafka installations — and how to avoid them
Apache Kafka is a distributed streaming platform designed for real-time data processing. Think of companies...

Kafka’s TCO: Much Bigger Than Its Price Tag
Unveiling the Hidden Costs: Why Kafka’s True Expense Goes Beyond Licensing Fees
