


Apache Kafka Use Cases: When To Use It & When Not To

Introduction
Microservices and event-based application architectures have revolutionized the modern application landscape. Gone are the days when batch-based processing was acceptable. These days, architects strive to achieve near-real timeliness and completely decoupled application architecture to meet the speed and availability requirements. Decoupled applications typically use an event management system r to facilitate integration between various services. Event sourcing-based architectures where application logic is represented entirely in terms of events is another area where an event store is used.
Apache Kafka is an open-source framework that can be used to implement data integration services, streaming analytics applications, and high-performance data pipelines. Kafka is basically a distributed event store and stream processing framework that can be used in multiple forms like a queue management system, message broker, event store, etc. This article will discuss the basic concepts of Kafka and the typical use cases where it will be a good fit. The article will also cover some cases where Kafka will be a misfit.
Need for Kafka?
Before going into the concepts of Kafka, let us spend some time understanding the basics of event streaming. Event streaming deals with capturing real-time data from sources like databases, IoT devices, sensors, cloud components, etc as a continuous stream. Processing this data requires a store that can keep the events durably in the order of reception. Most applications relying on such events require processing them and reacting to them in real-time as well as retrospectively. They will also require routing them to other services. Event streaming platforms facilitate the capturing, storing, and processing of such events.
Let us explore the concept of event streaming through an example. Imagine a global eCommerce website serving orders for thousands of customers every second. Such websites usually have a web of hundreds of microservices to cater to different parts of the operation. Diving the operations to multiple services helps such organizations to develop and deploy in a purely decoupled fashion with globally distributed development teams. A Search platform, an inventory management system, an order management system, a shipping management system, etc are typical components found in an eCommerce organization.
When a customer places an order an event gets generated and routed to multiple platforms that react based on it. For example, the inventory management system updates the remaining quantity of the item, the order management system generates another event for the payment processing module, and the shipment processing system creates an event for initiating shipping. You might wonder if the same sequence of actions can be executed using synchronous API calls. Such an approach will not work for a high volume of transactions and will result in choked services.
This is where an event streaming platform comes in. The event streaming platform stores the events and routes them to appropriate services. Developers can maintain and scale such a system independent of other services. Kafka fits great into such a requirement since it is an all-in-one package that can be used as a message broker, event store, or stream processing framework.
Understanding Kafka
Kafka is an open-source even streaming platform that can also act as an event store. It can also be used as permanent storage. In a nutshell, Kafka combines three functionalities into one.
- To publish and subscribe to a stream of events. It can also be used in a producer-consumer style where multiple consumers can feed from the same consumer.
- To store events durably for any period of time.
- To transform events and react to them in a real-time manner.
Kafka is a distributed system, consisting of servers and clients that communicate over a network. Kafka servers are usually run as a cluster. The ones that serve as the storage layer are called brokers. There is another set of servers that form the Kafka-connect layer which is responsible for connecting to source databases and feeding data. In case a server fails, Kafka is intelligent enough to route the work to other servers and not let the high-level objective take a hit.
Kafka clients are application codes that process the data. Kafka client is available for multiple programming languages like Python, Java, Scala, Go, etc.
Producers and Consumers are completely decoupled in Kafka. This means, they can even be written in different programming languages or exist on physically separate servers.
Kafka organizes events into a concept called topics. Topics are logic groups of events from which consumers or subscribers can accept events. Kafka topics support multiple producers and multiple consumers. The topics store messages even after they are read by the consumers.
Kafka topics support partitions, Partitions are stored in different broker servers to provide scalability. This helps clients to interact with multiple brokers at the same time. Kafka guarantees that events written to a partition will be read in the same order as they are written. Only a single consumer can process messages in a topic partition.
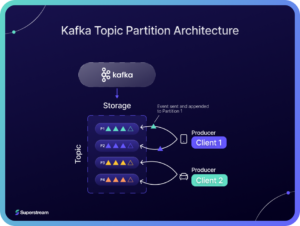
The above diagram shows the topic partition concept in Kafka. There are four partitions for the same topic and two clients. Both clients are adding messages to the same topic but to different partitions. Multiple producer clients can add data to the same topic at the same time. The messages that are appended to a specific partition is always consumed in the same order by the consumers.
Kafka supports fault tolerance by replicating the topics across physically separated servers. In case one server goes down, it does not affect the cluster because of partitioned topics. A topic partition replication factor of 3 is typically used in production workloads.
Kafka uses a pull-type mechanism for consumers. This helps the consumers to process data at their own pace and not be overwhelmed by the pace of the producers. This also helps in optimal batching. Pull-based mechanisms, usually suffer from the problem of the consumer getting blocked in a loop in case the data never arrives. Kafka works around this problem by providing parameters to optimize this waiting time.
Kafka uses the concept of consumer groups to reduce the overhead related to the acknowledgments. Consumer groups are a logical collection of consumers that deals with a specific activity. Kafka topic partitions are ordered and it ensures that only one consumer within the same consumer group processes a topic partition. A consumer can also roll back to offset in history and start processing it again.
Kafka provides three kinds of message guarantees – At least once, at most once, and Exactly once. It uses at least-once guarantee by default and retries in case a message written is not confirmed. One can disable the retry logic at the producer to use the utmost-once guarantee. To use an exactly-once guarantee, developers should use Kafka streams that support transaction features.
Kafka Strengths
Now that we understand the concepts behind Kafka’s architecture, let us spend some time understanding the strengths of Kafka and how the architecture helps it achieve them.
High Availability
Kafka is highly available. The high availability comes from the cluster-based implementation of brokers. This helps Kafka to stay available even if a server goes down. Kafka is intelligent enough to route requests to other brokers when one of the servers faces problems.
High Durability
Kafka is highly durable. Durability is about reducing the chances of losing messages. Kafka uses the concept of acknowledgment to identify the loss of messages and retry sending them. Kafka’s exactly-once guarantee provides the ideal form of durability, even though only in the case of Kafka streams.
High Scalability
Kafka is easily scalable. Kafka’s cluster-based nature helps developers to scale it horizontally. Scaling Kafka can be done by adding more servers for the brokers. Kafka’s topic partition allows multiple consumers to consume front the same partition in an orderly manner.
Support For Message Transformation.
Kafka is a message broker with support for transformation. A message broker can transform the format of the incoming messages and push it to destinations with different input formats. This helps Kafka to integrate decoupled services.
Kafka supports content-based routing
Kafka can route messages to different destinations based on the content of messages. This allows the producers and consumers to be truly decoupled. The content-based filtering and routing enable provide basic ESB features to Kafka.
Support For High Data Volume
Kafka can handle a high volume of data. The distributed nature of brokers and support for multiple consumers for the same topics helps it to handle a large volume of data compared to other message brokers like ActiveMQ, RabbitMQ, etc. Hence Kafka is suitable for applications like clickstream analytics, IoT sensor data ingestion, etc where a large amount of data is sent to the broker in a short span of time.
Comprehensive Connector Support Through Kafka Connect
Kafka Connect module handles all the complexities of connecting to different data sources and destinations. As of now, it supports most of the standard data sources including, relational databases, nonrelational databases, and even cloud-based sources like AWS S3 and Azure Event Hub.
Low Latency
Kafka exhibits the lowest latency among its peers even while handling hundreds of MBs of data at a time. Developers can adjust the Kafka configuration parameters to get the best balance between throughput and latency for their application. The number of partitions, batching, compression, acknowledgments, consumer batched fetching, etc are some of the parameters that directly affect latency and throughput.
Kafka Use Cases
Kafka is a good fit for use cases where a highly available and durable message processing layer is required. It is also good at handling real-time requirements with short service level agreements. Its message transformation and routing abilities help it pose as a service bus as well in specific requirements. Kafka can handle a high volume of event data and hence it is used in domains like user behavior analytics, logistics, etc. Kafka’s stream processing abilities and comprehensive connector support are also valuable in such requirements. Let us now go through some of the use cases where Kafka is a good fit.
IOT Platform Using Kafka
IoT platforms deal with event data sent from millions of devices across the world. Let us consider a logistics provider who wants to track his shipments in real-time. The organization wants a dashboard where data regarding all the shipments is shown in real-time. The dashboard should show up alerts in case a shipment has not sent data for a predefined interval of time. Another typical requirement is to show up the average speed of shipment over the last few minutes or hours. The organization can also use features like estimated time of arrival, the average time taken for frequent routes, etc to finetune their business strategies.
Such requirements usually involve a device that can send data about the location of the truck at frequent intervals. The interval is typically in the range of ten to thirty seconds. Now imagine, thousands of trucks or shipments sending this data in a ten-second interval.
Solving this problem requires ingesting millions of events in tens of seconds, processing them, and updating the results to the dashboard in real-time. Not only that, developers need to route data to multiple databases or services depending on the complexity of the low-level requirements. Kafka can serve as the data processing platform for these requirements.
Let us design the architecture for such a requirement now. The IoT devices generally use protocol abstraction layers other than HTTP to send that data. This is to reduce the data transfer volume and the overhead of frequent connection initiation. MQTT is one such protocol. Since Kafka Connect supports MQTT, it is easy to integrate the protocol into the platform. The data reception part of the architecture will involve an MQTT endpoint and an integrated Kafka cluster. The devices can thus send data in MQTT format to these endpoints, which will push the data to a Kafka cluster.
The data processing requirement here has two aspects – The first one is the real-time aspect where the platform generates alerts based on the nonavailability of data or meeting threshold conditions. Kafka provides an SQL layer that can process streaming data and handle such requirements. The second aspect of data processing is the aggregated metrics or reports. For example, the organization needs a report on all shipments that were delayed the previous day. This requires storing the data in a database and building reports over it. Kafka can route raw data as well as minute-level or hour-level aggregated data to one of the services that will store data in a database. The complete architecture of the system will look as below.
![]()
As evident from the details above, Kafka is a great fit for such a requirement. Since the underlying streaming platform is horizontally scalable, the organization can simply add more nodes when it wants to increase the number of devices. Kafka’s message guarantees that will take care of the data loss. Routing logic support in Kafka will help route data to any number of auxiliary services. And last but not least, the platform will have high availability thanks to the cluster-based architecture of Kafka.
Click Stream Analytics Using Kafka
Click Stream analytics is about deciphering browsing behavior patterns from raw click stream data. This involves capturing every single action the user makes in a website or mobile app and aggregating it at different levels to come up with ways to improve the product. Firstly, it helps organizations understand how users are interacting with their products. It helps them understand the time-consuming actions and the actions that lead to users leaving the website. It also helps them understand the popularity of various parts of their website or product. While there are many third-party software-as-a-service offerings that provide clickstream analytics, many organizations still choose to implement them to have more flexibility and deeper analytics.
The data source for a clickstream analytics platform is a website that customers use. Javascript modules embedded in websites capture every click the user makes and send it to the A single click stream event is generally a user action with its time stamp and the origin URL. For popular websites, this data can quickly explode because of the events that get generated when millions of users access the website at the same. Imagine the number of events that will come to Amazon’s click stream platform on a sale day. Handling this requires a scalable, flexible, and always-available architecture.
Since click stream events are frequent, developers typically use a socket server to capture them instead of HTTP endpoints. Javascript modules embedded in the website push click events to a socket server that directs the events to Kafka topics. The click events are analyzed in real-time to generate alerts regarding the rapid deterioration in user experience as well as to provide a real-time view of how users spend time on the websites. At times, the click stream events are also fed as input to the machine learning models to provide real-time recommendations.
Clickstream events are also stored in a searchable form for further analysis later. Elastic search is a common candidate for such a data store because of its quick retrieval features. Grafana, an open-source visualization analytics framework is a good fit for implementing the dashboard since there are no complex requirements here to justify developing a custom dashboard. Grafana integrates well with Elastic search and is a defacto framework for visualization for complex requirements. Developers can use the KSQL DB queries in Kafka to implement real-time features like the number of page views over the last ten minutes or the number of errors over a time period. The complete architecture will look as shown below.
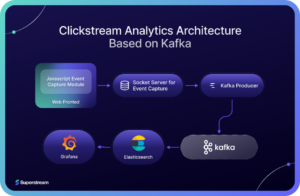
As evident, Kafka is a good fit here since this requirement needs a fault-tolerant, always-available, event platform. The organization can increase the number of instances for the broker in case the data volume increases. One can extend the same architecture to support multiple organizations or websites too since the underlying architecture is very scalable. KSQL features will help developers to implement aggregations easier than having to deal with a programming language. Kafka’s routing abilities will be a great advantage here to handle requirements like separating logged-in user’s events and guest-user events.
Data Integration Using Kafka
Modern organizations work on the principle of separate databases per microservice. This leads to a large number of data silos. Many services thus require data feeds from other platforms to work properly. A large organization usually has hundreds of such micro platforms resulting in a highly scattered data environment. Add to that, there are analytics requirements, that require a unified data store rather than data scattered all across the organization. Having a unified data store helps organizations derive value from their data quickly by deploying teams focused only on analytics. This is where a data integration platform can make a difference.
Let’s consider a retail chain that uses such a decoupled microservice-based architecture. The stores that are part of the retail chain use a point of sale application to record the sales and customer details. The business teams use an internal application to view details of the sales history for inventory planning and strategic decisions. The vendor integration team uses SAP to manage all the details of inventory catalogs and related invoices. The data from third-party sources Even without considering the other complexities of employee data, user data, etc, the technical team is dealing with a minimum of three data sources here. In an environment without a data integration platform, the development team implements ETL jobs across various sources and destinations to ensure that data updated in one platform reflects in other platforms.
A Kafka-based data integration platform will be a good fit here. The services can add events to different topics in a broker whenever there is a data update. Kafka consumers corresponding to each of the services can monitor these topics and make updates to the data in real-time. It is also possible to create a unified data store through the same integration platform. Developers can implement a unified store either using an open source data warehouse like Apache Kylin or use a cloud-based one like Redshift or Snowflake. In this instance, the organization uses BigQuery. Data to this warehouse can be loaded through a separate Kafka topic. The below diagram summarizes the complete architecture.
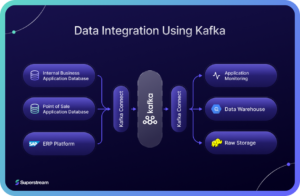
In this case, Kafka integrates data between two relational databases, an ERP platform and a data warehouse that is built on top of Hadoop. One might wonder about the development effort required to implement this setup. Kafka Connect helps to reduce the development effort here by providing source and sink connectors for most of the databases. It supports PostgreSQL and BigQuery. It comes with a plugin for fetching data from third-party sources like SAP through RestAPIs. In case of developers need to transform data while moving from one source to a destination, they can implement a Kafka streams application.
As evident, Kafka is a good fit for real-time data integration involving on-premise as well cloud-based data sources and destinations. Just like in the other examples, the organization can keep the number of instances low while the data volume is low and increase it gradually. That said, Kafka is not a good fit in the case of heavy ETL operations where transformation complexity is high. At its heart, it is a message broker, and time-consuming queries do not go well with Kafka.
Kafka For Event Sourcing
Event sourcing is an architecture pattern where the data is represented as a sequence of persisted events rather than the state of entities. The idea is that the journey of a system is reaching a particular state is as important as the final state itself. The event sourcing pattern comes with a built-in audit trail because of the way it is designed. It also provides information for richer analysis, especially from the sequence of events. Another advantage is the ability to recreate the state of the system at any point in time if data corruption occurs. The system can just replay the events in the order of reception and correct the state.
Let’s consider event sourcing from an eCommerce website’s perspective. Whenever a customer places an order, a traditional implementation will update the customer’s cart with the final state. In the case of an event sourcing-based architecture, an event corresponding to the cart update will be generated. Instead of storing the state of the cart, the system only stores these events. Now when the customer updates the cart, say delete an item, an additional event is generated and persisted. Whenever the current state of the cart has to be generated, the system replays the persisted events. The advantage of this approach is that it opens deeper analysis because the sequence of events is stored. For example, in this case, the sequence of events that lead to the final state of the cart is valuable for an analyst who works on cart abandonment.
Implementing such a system requires an event processing platform that stores events durably and can be scaled seamlessly when the data volume increases. The backbone of this system is an event sourcing database and Kafka can serve as a good event-sourcing database. In the case of the eCommerce retailer mentioned here, the website backend can drop events to Kafka through a backend API whenever events happen and the backend microservices can react to those events in real-time. The below diagram summarized the architecture.
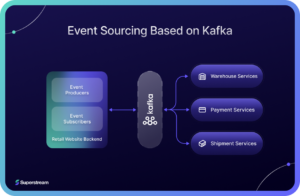
As detailed above, Kafka is a great fit here, because it can store the events durably and ensure zero message loss. The message guarantee is very important here since the consumer website depends on the successful processing of the events. Losing customer orders is disastrous for an eCommerce website. Kafka’s high throughput and scaling features will come in handy when the customer volume increase.
Kafka For Log Aggregation
Most organizations use containers to deploy their applications these days. While containers provide a great way to ensure resilience and availability, they pose challenges in log management because of their stateless nature. Developers can not access the logs once the pod dies because of this stateless nature. Hence centralized logging is very important in such deployment architecture. Centralized logging involves capturing logs of hundreds of containers and pushing them to a central repository, from where they can be analyzed. Centralized logging also opens up opportunities for generating real-time alerts based on specific conditions.
Implementing centralized logging requires a streaming platform that can ingest log files from a large number of locations. The sources could be on-premise deployments, cloud-based deployments, or even hybrid cloud deployments. As the enterprise expands, the number of microservices and thereby log sources can grow rapidly. Hence the streaming platform must be scalable, with high throughput and low latency. It should also have real-time stream processing features to generate alerts based on threshold values. Developers usually run a searchable database and a visualization tool integrated with the streaming platform to generate further insights.
Implementing centralized logging also needs changes in the application code. Frameworks like OpenTelemetry provides SDKs and APIs for implementing instrumentation logic to application code in a vendor-agnostic way. OpenTelemetry supports automatic instrumentation, using which developers can implement logging without having to write much code. The streaming platform of choice should integrate with the instrumenting frameworks like OpenTelemetry for ease of implementation.
Kafka is typically used to implement log aggregation systems for many reasons. Kafka provides a scalable platform with low latency real-time analytics. Frameworks like OpenTelemetry provide Kafka exporter libraries to ease the implementation of log aggregation using Kafka. You can find a Kafka-based log aggregation system architecture below.
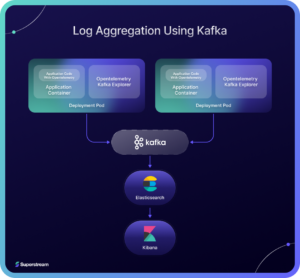
The above architecture uses Elastic Search for storing the logs in an indexed form. It used Kibana as the visualization tool on which dashboards and metrics can be implemented. The application code uses OpenTelemetry Kafka exporter to push data to Kafka. Kafka consumers can push ingested data in specific topics directly to Elastic Search. One can use KSQL queries to generate alerts and then push to a topic designated for alerts. Consumers can then pick it up to send notifications to stakeholders. Minute level or hour level aggregation is another feature where KSQL queries can be used in this content.
When Not To Use Kafka
While Kafka has its merits when it comes to stream processing, it is not a one-size-fits-all solution to all the data problems. Kafka’s distributed nature and its focus on streaming nature are great for certain use cases. But there are many use cases, where Kafka will be a misfit because of its limitations and design considerations.
Kafka is not an ETL tool
Even though Kafka has stream processing features, it is not an ETL tool. An ETL tool deals with complex transformations that can use up a lot of time and resources based on the complexity. Kafka will not be fit in such cases. Kafka’s advantage is its real-time data processing abilities. So it fits well with real-time analytics use cases that can be implemented using SQL queries. Kafka will be a misfit for ETL requirements other than this.
Light Weight Use Cases With Little Data
Being a distributed system, Kafka is best suited for processing a large number of events. It will be an overkill for use cases where data volume is low. A distributed system has many overheads that are justified only by sufficient data volume. For low-volume workloads, these overheads impact the overall throughput and cost-benefit ratio. Hence Kafka will be a misfit in case of light use cases.
Requirements With Complex Message Transformation
Even though Kafka has querying language support, it is not a good fit for transformation requirements with high complexity. For example, KSQL does not support user-defined functions or user-defined table functions yet. Also, Kafka streams do not support checkpointing which is a useful feature to store states. If the requirement has complex message transformation, one should consider using Spark Streaming with Kafka rather than Kafka streams,
Kafka Is Not A Database
One should not use Kafka as a database even though it boasts of durable event storage. Event storage is a whole different paradigm compared to a database. It is used in specific architectural patterns where event transformation and real-time analytics are required. Typical database features like indexes, transactions, etc are absent in Kafka and one should not use it as persistent storage unless there is real-time transformation involved. Joins in Kafka return unlimited results because of the windowing concepts. It can not replace the join in a traditional database.



