


















4 things wrong with most Kafka installations — and how to avoid them
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Duis porttitor consequat lectus eget pharetra.

Apache Kafka is a distributed streaming platform designed for real-time data processing. Think of companies like Lyft and Spotify—they leverage Kafka’s high throughput and fault tolerance for everything from log aggregation and real-time analytics to event sourcing of continuous data streams.
But let’s be real—getting Kafka up and running smoothly is no picnic. In this article, we’re going to explore real-life Kafka installation pitfalls.
We’ll tackle three common obstacles and shower you with practical tips on how to overcome them. So, strap in and read on.
A Quick Look at Kafka’s Distributed Architecture
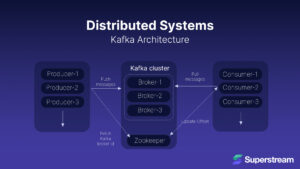
Let’s imagine Kafka’s architecture as a well-oiled postal service:
- Brokers: Think of brokers as the central post offices. Each office stores packages (data) and handles various delivery requests (client requests). Just as post offices manage the mail flow, brokers manage the data flow.
- Topics: These are the delivery routes. Each route is divided into several segments (partitions), allowing multiple delivery vans (data streams) to operate simultaneously, ensuring efficient and parallel processing.
- Producers: Producers are the check-in desks where senders (applications) drop off their packages (data) for specific routes (topics).
- Consumers: Consumers are the delivery destinations where recipients (applications) pick up their packages (data). Consumers can work in groups to manage the load effectively, like having multiple delivery points for the same route, ensuring balanced and reliable data retrieval.
- Zookeeper: Zookeeper is the central control hub, coordinating the entire postal network. It tracks all post offices (brokers) and ensures smooth, orderly, and efficient operations across the network.
1. Misconfigured Replication Factors
It’s Monday morning at the headquarters of a fast-growing eCommerce platform. The team is excited about the new features they’ve been rolling out, and everything is running smoothly.
But, during the initial setup of the Kafka cluster, the team, under tight deadlines, set the replication factor to 1, thinking they would adjust it later. However, as the platform grew and more pressing issues arose, they just didn’t.
Around 11 AM, an unexpected power surge hits the data center where one of the Kafka brokers is hosted. This broker crashes and becomes inaccessible. It is responsible for critical partitions holding recent transaction data, including customer orders, payment confirmations, and inventory updates. Since the replication factor is 1, these partitions had no replicas on other brokers.
Realizing that the crashed broker’s partitions have no replicas, panic sets in as the engineering team understands how screwed they are.
How could this have been prevented?
- Set a replication factor: The replication factor dictates how many copies of your data are kept across different brokers in a Kafka cluster — it should be set to at least three.
- Make good use of acknowledgments: Setting
acksto “all” means that all replicas must acknowledge the write before it’s considered successful. - Create In-Sync Replicas (ISRs): ISRs are replicas that are up-to-date with the leader. Aim for at least 2 in-sync replicas per partition.
Why is this the solution?
- Set a replication factor: Increasing the replication factor means that if one broker goes down, other brokers still have the data.
- Make good use of acknowledgments: This prevents data loss if a leader broker fails after acknowledging a write before the data is replicated to followers.
- Create In-Sync Replicas (ISRs): Ensuring multiple ISRs means that even if the leader fails, another ISR can take over with minimal data loss, maintaining the integrity and availability of your Kafka deployment.
2. Ignoring Kafka Client Library Changes
The development team is hard at work at a major financial institution known for its vast network of services. With pressure mounting from upper management to roll out new features, the team has just completed an upgrade to the Kafka client libraries.
In their haste, the team skipped a thorough review of the release notes and bypassed testing the new client libraries in a staging environment. Given Kafka’s reputation as a robust platform, they assumed things would be alright and pushed the changes directly to production.
Hours later, the customer service team was overwhelmed with calls and emails from high-net-worth and corporate clients, who were furious about missing or delayed transaction records.
The engineering team realized that the problems were due to the unreviewed and untested client library changes. Now, the team faces the daunting task of rolling back the upgrade and restoring the system’s stability.
How could this have been prevented?
- Review the release notes: That includes not only the Kafka client library but also its dependencies.
- Test in staging: The staging environment should mimic your production setup as closely as possible.
Why is this the solution?
- Review the release notes: Release notes provide a detailed account of what has changed in the new version of the library, which could include bug fixes, new features, performance improvements, and breaking changes. For example, changes in how messages are batched or acknowledged could affect message ordering and delivery guarantees. This will help you understand how the changes made might impact your system.
- Test in staging: Proactive testing makes sure that the upgrade does not introduce instabilities or unexpected behaviors into your production environment. You can identify potential issues, such as changes in message ordering, performance degradation, or compatibility problems, before they can affect your live production system.
3. Lack of Properly Distributed Infrastructure
The office is a hive of activity at a leading healthcare technology provider. Medica prides itself on delivering reliable, real-time data processing to support critical medical and ensure the smooth functioning of its healthcare management systems.
The team set up a Kafka cluster to handle the increasing volume of real-time patient data. However, they decided to deploy the entire Kafka infrastructure in a single data center due to budget constraints. They believed the data center’s existing redundancy measures would suffice for high availability.
One Wednesday afternoon, disaster struck: a significant fire broke out in the data center. The fire suppression systems were activated, but only after the fire caused substantial damage to the servers, including the Kafka brokers. The consequences took effect immediately.
This disruption endangered patients’ lives as critical data on vital signs and alerts became unavailable. The vulnerability of the single data center deployment quickly became obvious. Now, they have to restore services and ensure patient data becomes available again.
How could this have been prevented?
- Distribute the deployment: Use a variety of availability zones or data centers.
- Use Cross-Data-Center Replication (CDCR): This replicates your data across different locations.
Why is this the solution?
- Distribute the deployment: Deploying Kafka across multiple availability zones or data centers creates resilience because if one spot hits a snag, the others keep humming along without a hitch. This redundancy is key for keeping things running smoothly no matter what, even if one region goes down.
- Use Cross-Data-Center Replication (CDCR): Cross-data-center replication (CDCR) involves setting up Kafka to replicate data across different geographic locations. This means that data produced in one location is continuously backed up to a completely different part of the world. In the event of a failure at one site, the replicated data at another site can be used to continue operations without data loss.
4. Corrupted Data Failures
At a leading provider of smart agricultural technology, the company relies heavily on real-time data streaming to manage sensor data, monitor crop health, and support precision farming.
The team set up a Kafka cluster to handle the increasing volume of sensor data from various farms. However, they needed to configure failure-handling strategies adequately.
One Tuesday afternoon, a set of faulty soil moisture sensors started sending corrupted data messages, causing the Kafka consumers to fail when processing this corrupted data.
On several large farms, real-time crop health monitoring systems, which relied on Kafka for continuous data feeds, started lagging. This delayed transmitting vital information about soil moisture and nutrient levels, risking crop damage. The lead Kafka engineer sprang into action, coming up with robust failure-handling strategies to manage such incidents in the future.
How could this have been prevented?
- Implement consumer groups: Consumer groups distribute message processing across multiple consumers.
- Set up retries with exponential backoff: Configure the application to retry requests that ended in errors. Increase the wait times exponentially between each successive attempt so you don’t overwhelm the system.
- Use Dead Letter Queues (DLQs): Capture messages that fail repeatedly in a Dead Letter Queue, something you can regularly check to identify the root causes of the failures it records.
- Proactively monitor the cluster: Set up comprehensive monitoring for your Kafka cluster by tracking critical metrics like message lag, broker health, and partition availability. Set up alerts for whenever any metrics pass critical thresholds.
Why is this the solution?
- Implement consumer groups: Multiple consumers to read from the same topic with built-in load balancing, fault tolerance, and parallel processing with a consumer group. If one consumer fails, others can continue processing.
- Set up retries with exponential backoff: This increases the likelihood that the system overcomes temporary issues and succeeds on successive tries.
- Use Dead Letter Queues (DLQs): These are a safety net for messages that cannot be processed after multiple attempts. By diverting these problematic messages to a DLQ, you prevent them from blocking the processing of other messages. Regularly reviewing DLQ contents helps identify and isolate recurring issues and improve overall system reliability.
- Proactively monitor the cluster: This involves tracking your Kafka cluster’s key performance indicators (KPIs). Critical metrics like message lag indicate delays in processing, while broker health and partition availability highlight infrastructure issues. Setting up alerts for these metrics makes sure we detect and resolve these problems promptly.
Closing thoughts
Kafka is an incredibly powerful platform for handling real-time data streams, but it’s not without its challenges. As we’ve seen through these real-world scenarios, failures can have severe consequences, from lost data and disrupted services to missed opportunities and unhappy customers. This is where Superstream comes in.
Superstream acts as a client to your Kafka Clusters to continuously retrieve various metadata and samples from each topic’s stored data. This collected data is continuously analyzed using a pre-trained neural network, which generates a detailed report identifying potential improvements and pinpointing specific areas of optimizations.
Say goodbye to oversights and unexpected failures. Embrace the power of Superstream and unlock the full potential of your Kafka deployments. Try Superstream today and experience the future of real-time data processing.
No content available.
Related Articles

How to reduce AWS MSK costs
Optimize Your Budget: Proven Strategies to Cut AWS MSK Expenses

Warpstream is Dead. Long Live Cost Awareness
Embracing Cost-Aware Strategies After Warpstream

Kafka’s TCO: Much Bigger Than Its Price Tag
Unveiling the Hidden Costs: Why Kafka’s True Expense Goes Beyond Licensing Fees
